Pose estimation is a fascinating field within computer vision that aims to determine the precise 3D position and orientation of objects or human bodies in images or videos. It plays a crucial role in various applications, including robotics, augmented reality, virtual reality, human-computer interaction, sports analysis, and surveillance systems. By accurately estimating the pose, computers can perceive and understand the physical world, leading to a wide range of practical advancements.
In this article, we will delve into the realm of pose estimation, examining its fundamental concepts, methodologies, and cutting-edge techniques. We will explore the diverse approaches used in the field, including skeletal modeling, multi-view geometry, and deep learning-based methods such as OpenPose and DensePose. By shedding light on these techniques, we hope to provide a comprehensive understanding of pose estimation and its practical implications.
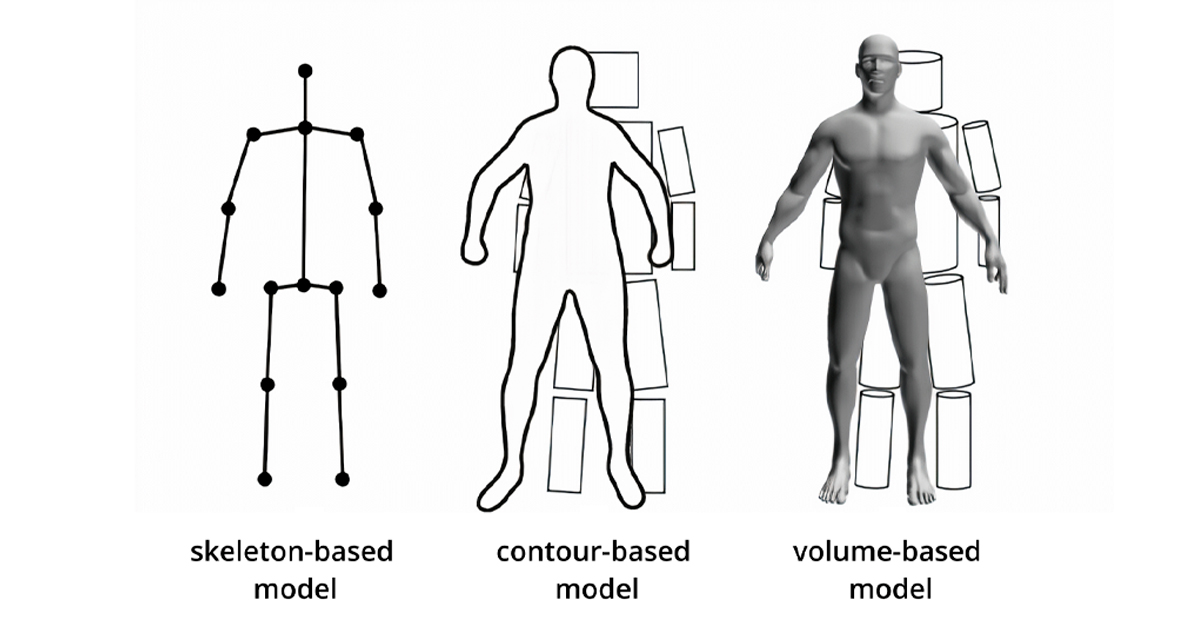
1. Skeletal Modeling
Skeletal modeling is a traditional approach to pose estimation that represents objects or human bodies as a collection of interconnected joints or keypoints. This method relies on prior knowledge of human anatomy or object structure to infer the pose. By detecting and connecting keypoints, skeletal models can estimate the 3D position and orientation accurately.
One commonly used skeletal model for human pose estimation is the human body model, which typically consists of joints representing major body parts such as the head, shoulders, elbows, wrists, hips, knees, and ankles. By analyzing the relative positions and orientations of these joints, skeletal modeling algorithms can infer the pose of a human body in an image or video.
However, skeletal modeling approaches often face challenges in accurately estimating poses when dealing with occlusions, complex articulations, or cluttered backgrounds. To overcome these limitations, researchers have explored alternative techniques, including multi-view geometry and deep learning-based methods.
2. Multi-View Geometry
Multi-view geometry is a powerful technique for pose estimation that utilizes multiple camera views to triangulate the 3D position of keypoints. By combining information from different perspectives, multi-view geometry algorithms can achieve more accurate pose estimations compared to single-view methods.
In multi-view geometry, a set of correspondences between keypoints in different camera views is established. Using triangulation algorithms, the intersection of the corresponding rays originating from each camera is computed, resulting in the 3D position of the keypoints. This process leverages the principles of projective geometry and camera calibration to reconstruct the scene in three dimensions.
Multi-view geometry-based pose estimation is widely used in applications such as motion capture, 3D reconstruction, and robotics. However, it relies heavily on the availability of multiple synchronized camera views and accurate camera calibration, making it less applicable in scenarios where these requirements cannot be met.
3. Deep Learning-Based Approaches
In recent years, deep learning has revolutionized the field of pose estimation by enabling the development of highly accurate and robust models. Deep learning-based methods leverage the power of artificial neural networks to learn intricate patterns and relationships from large-scale annotated datasets.
One notable deep learning-based approach in pose estimation is OpenPose. OpenPose employs a convolutional neural network (CNN) to detect keypoints and infer the connections between them. By analyzing the pixel-level information in images or videos, OpenPose can estimate human poses in real-time, even in challenging scenarios such as occlusions and complex poses.
Another significant advancement in deep learning-based pose estimation is DensePose. Unlike skeletal modeling or keypoint-based approaches, DensePose aims to provide dense surface correspondence by associating each pixel in an image with a 3D point on the object or human body surface. This fine-grained estimation allows for detailed understanding and analysis of poses, enabling applications such as virtual try-on, augmented reality, and 3D character animation.
Deep learning-based pose estimation techniques offer significant advantages over traditional methods, as they can automatically learn representations and feature hierarchies directly from data. However, they require large amounts of annotated training data and substantial computational resources for training and inference.
Summary
Pose estimation plays a pivotal role in computer vision, enabling machines to perceive and understand the 3D position and orientation of objects and human bodies in images and videos. By employing techniques such as skeletal modeling, multi-view geometry, and deep learning-based approaches like OpenPose and DensePose, researchers have made significant strides in accurate and robust pose estimation.
The field of pose estimation continues to evolve, driven by advancements in machine learning, sensor technologies, and computational capabilities. As pose estimation techniques become more sophisticated and accessible, we can expect to see further integration of this technology in various domains, including robotics, healthcare, entertainment, and more.
Ultimately, the progress in pose estimation will contribute to the development of more intelligent and interactive systems that can perceive, analyze, and interact with the physical world, leading to exciting opportunities and transformative applications in the years to come.